There are different custom scripting tools to handle data. Still Why we need a framework to process big data? The thing is data is growing rapidly each day. Research suggests that stored data in our world will be double in every 18 months. The ever growing data cannot be logically fit to one machine. Even it does, processing time increases as the size of data increases. To encounter this problem MapReduce built to concur. Parallelizing the processing power of the device with distributed system solve the problem.
![]()
Which speeds up the big data processing as compared to single machine algorithm. This worked for a while but it has multiple of difficulties - Algorithm complexity, long running batch jobs, disk oriented. Then Apache interduces Spark to solve those difficulties.
Spark uses a lot of optimization in same Hadoop computation against the fraction of the resources while still another magnitude faster. It sets new record in file sorting benchmark in 2014.
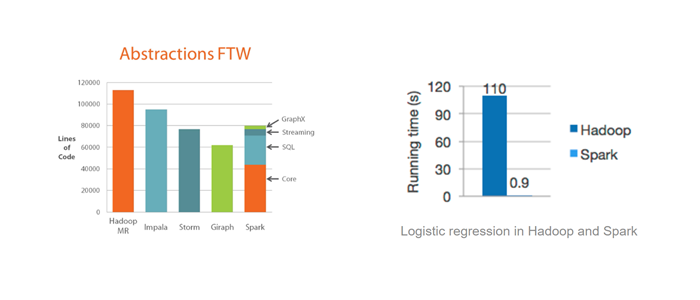 Hadoop MapReduce used 2100 machines and took 72 minutes. This means that Spark sorted the same data 3X faster using 10X fewer machines. All the sorting took place on disk (HDFS), without using Spark’s in-memory cache. [1]
There is another important thing - Big Data means big code. Spark only require a lot less core count compare to MapReduce. Spark generalize abstraction and provide more tiny code which increases readability, expressive code, fast, testability, Interactive, Fault tolerant, unify big data.
This introduction gives the overview of why spark comes into the light even though there is Hadoop project from Apache.
Hadoop MapReduce used 2100 machines and took 72 minutes. This means that Spark sorted the same data 3X faster using 10X fewer machines. All the sorting took place on disk (HDFS), without using Spark’s in-memory cache. [1]
There is another important thing - Big Data means big code. Spark only require a lot less core count compare to MapReduce. Spark generalize abstraction and provide more tiny code which increases readability, expressive code, fast, testability, Interactive, Fault tolerant, unify big data.
This introduction gives the overview of why spark comes into the light even though there is Hadoop project from Apache.
History of spark
First public paper on MapReduce was released in 2004. That lead to the birth of the Hadoop in 2006 at yahoo. That the beginning of modern big data computation.
In 2009, Spark was originally developed at the University of California, Berkeley’s AMPLab. This was actually a Ph.D. paper [“spark cluster computing with working sets” University of California, Berkeley link ] of Matei Zahari which is released in June 2010. Same year made project open source under BSD licenses. The project became to get ground while being incubated in Berkeley AMPLab. In 2013, Matei Zahari and groups of programmer started data brick. The Spark codebase was donated to the Apache Software Foundation that has maintained it since. Spark changed its licensing to Apache 2.0.
Since then, It’s become Apache top level project. Its braked the record of data sorting in 2014. Still it is one of the active big data projects which continues to grow in the big data world. More than 500 companies are using it in 2015. It generalized abstraction and growing helping library result to use spark vast number of uses – such as Pandora real time recommendation system. Companies like Yahoo, Comcast, Ooyala, convivial, Netflix, eBay (for log analysis), twitter (graph analysis of social network), home Janelia (analyzing brain pattern in real time). It uses only be limited in the extent of your imagination.
Programming Model
First few years of MapReduce release lead to Hadoop which leaps the big data. Many companies start using it. Later it is realized that mapReduce is restricted in design with a narrow focus. Specifically, batch procession. This over-specification leads to an explosion of specified library each adding new API to juggle data model.
Hadoop need third party software to handle the different task. For instants, storm or scalding is used for streaming data, Hive for data queries and so on. It also concludes that Hadoop requires much more code to execute small text from abstraction FTW figure. Only Hadoop MR code is more than spark code including all APIs codes.
Spark aims a unified platform for big data. And all these features originate from core library. any addition to the library will automatically gain by core. Which enhance its performance. The core is very generalized so extending it is very simple and straight forward. It designed data frames API on the top of another add-on library to continuing unifying ecosphere.
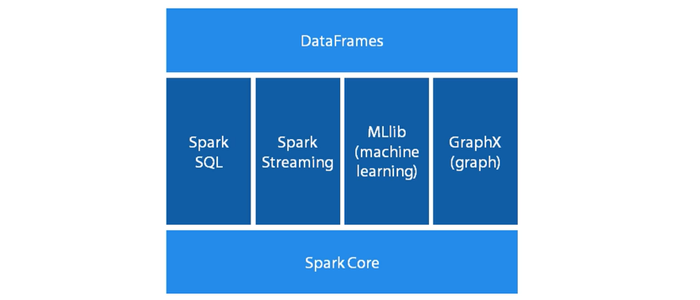
It is an open source and public available its code in Github. The core of spark is maintaining by a lot of programmer including its creator Matei Zaharia. Scalable other refined library builds on the top of the core API.
Resilient Distributed Dataset (RDD)
These are the collection of elements partitioned across the node of the cluster that can be operated on in parallel. It is an interface designed that makes it seems like any other collections, though. From this, the work is distributed across the cluster of the machine. So that computation against it run in parallel by reducing time in order of magnitude. This mechanism ensures that if one machine fails rest of the machines continue to work. Instead of executing those function immediately, the instructions are stored for later used which refer as Directed Acyclic Graph (DAG). This graph of instructions continues to grow through the series of call transformation such as map, filter … Another number of lazy operation. DAG are passed to each worker nodes and each not has information of best way to recover while any node is false. Still action has not done. Actions which execute the task against the data. Actions have collected, count, reduce … methods.
RDD is distributed across the cluster and executed in a parallel. Spark context task is transfer to each worker node and execute task individually as quickly as they can. Once all the node completed their task, then next stage of DAG will be triggered and repeated until all the graph has been completed.
Implementation
Language Support
More than one language support spark. Most compatible is scala because spark itself written in scala. Compatible to java, also support python (some feature does not support), In 1.4 and later release spark even support R programming language.
Hello World
Spark come with the shell that can run the interactive query. Spark shell is same as regularly scala application interactive shell except some minor modification. That how a spark could bring interactive query in big data.
Start with typing
$ Spark-shell
When it runs by spark-shell commend. Shell automatically added two contexts for you, sc and sqlContext. Where sqlContex is for spark SQL library and sc is Spark context. SC is the main starting point for spark application.
The word count of README.md file of spark package using spark shell.
Scala> val textFile = sc.textFile(file:///Spark/README.md)
Output :
textFile: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at textFile at
:21
The result is in the form of RDD. Most basic abstraction of spark. It is called RDD because it is resilient distributed datasets. No matter how long the text file is it give immediate feedback because it’s just abstraction of operation that is being declared.
We just tell the spark to load the file. Spark core operation is split into two categories – transformation and action. Transformation is lazily evaluated only storing the instant. Until action will execute the result are actually computed. It can be done by executing the first method.
Scala> textFile.first
res6: String = # Apache Spark
This action retrieves the first line of text file. This shows readme text file contain string call “# Apache Spark”. There are many benefits spark’s lazinesses, this is because it doesn’t have to read the entire file only the first line.
Next step to map each line of the file, splitting into an array of space delimited word. And floating resultant sequence of string array into a single long sequence.
Scala> val arrangedFileDatasSet = textFile.flatMap(line => line.split(“”))
arrangedFileDatasSet: org.apache.spark.rdd. RDD[String] = MapPartitionsRDD[2] at flatMap at
:23
Now we have new RDD which is long sequence of an array of words. It should be setup out sequence for counting each word into a key value pair. Where word is key and value is count.
val countPrep = arrangedFileDataSet.map(word => (word,1))
countPrep: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at
:25
With the data prepared in key value format now we can reduce the value down to the single count for each key. Adding up all the ones in each word basket.
val counts = countPrep.reduceByKey((accumValue,newValue) => accumValue+ newValue)
counts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at
:27
Again sort the word count lists.
val sortedCounts = counts.sortBy(kvPair =>kvPair._2, false)
sortedCounts: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[9] at sortBy at
:29
False mean in descending order. And._2 mean accession object in second position of tuple.
All of the above processes are chaining of the transformation of data. So the lazy nature of transformation means that none of the data has been processed yet.
Finally, the code to save our work in a file.
sortedCounts.saveAsTextFile(“file://myData/ReadMeWordCount”)
This creates a folder in the directory that we define ReadMeWordCount.
 Spark unified model of combining processing with machine learning and streaming and other utilities brought by its library often means of the complete workforce all be contain in spark. It’s a general propose computing framework that capable of handling many different distributed systems.
Spark unified model of combining processing with machine learning and streaming and other utilities brought by its library often means of the complete workforce all be contain in spark. It’s a general propose computing framework that capable of handling many different distributed systems.
All spark applications are managed via central point called Driver. The driver is a coordinator of work distributing it as many workers as configured. That driver management is handled through the starting point of any spark application – spark context. All other applications are built around this center manager which is like the conductor of a symphony; handling all the separate pieces of distributed application. So that it runs as smoothly as possible. It builds the execution graph that will be sent to each worker, scheduling work across those nodes, taking advantage of existing data location knowledge. Sending the work to the data so as to avoid unnecessary data movement across the network. Monitoring those task for any failure so it regenerates the same task to another worker.
In the previous example of word count using spark-shell, the file was read by spark context(sc). The standalone application sc must be defined first before its implementation.
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object WordCounter {
def main(args: Array[String]){
val config = new SparkConf().setAppName ("WordCounter")
val sc = new SparkContext(config)
val textFile = sc.textFile("file:///Spark/README.md")
val tokenizedFileData = textFile.flatMap(line => line.split(" "))
val contPrep = tokenizedFileData.map(word => (word,1))
val counts = countPrep.reduceByKey((accumvValue, newValue)=> accumvValue+newValue)
val sortedCounts = counts.sortBy(kvPair => kvPair._2, false)
sortedCounts.saveAsTextFile("file:///mydata/ReadmeWordCountViaApp")
}
}
First line inside of the main method create an object of SparkConf and is passed to Spark Context. The object should be full setup before passing to context. Once it passes to context then it became immutable with regard to that context. Any change with original config Object will have no effect on the application.
The file now time to package by using sbt tool.
$ sbt pakage
There is a file called build.sbt in the folder shown while packaging. File has application name and version of spark.
Now time to execute the application. Following shell script will execute the task.
$ Spark-submit –class “main.WordCounter” –master “local[*]”

Spark submit the class which we named WordCounter then we pass the address of master node. In this example, we use local machine. The number of core can be specified inside the brackets. For now, we just put a wild card in it. Then we have to provide a jar of spark application that we have packaged earlier.
These is the basic example of Spark implementation. Now your turn to dig deep into spark wide range of applications.